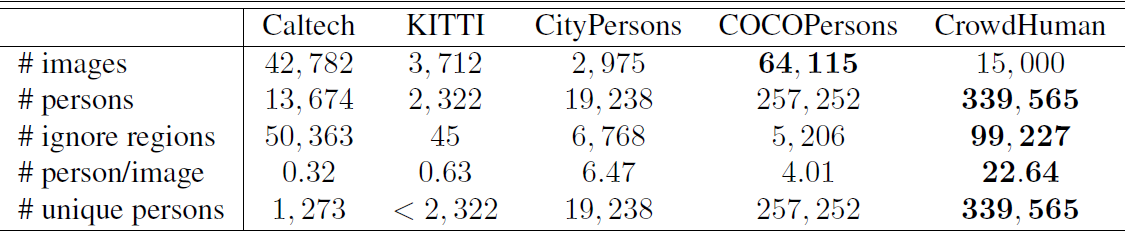
Volume, density and diversity of different human detection datasets.
For fair comparison, we only show the statistics of training subset.
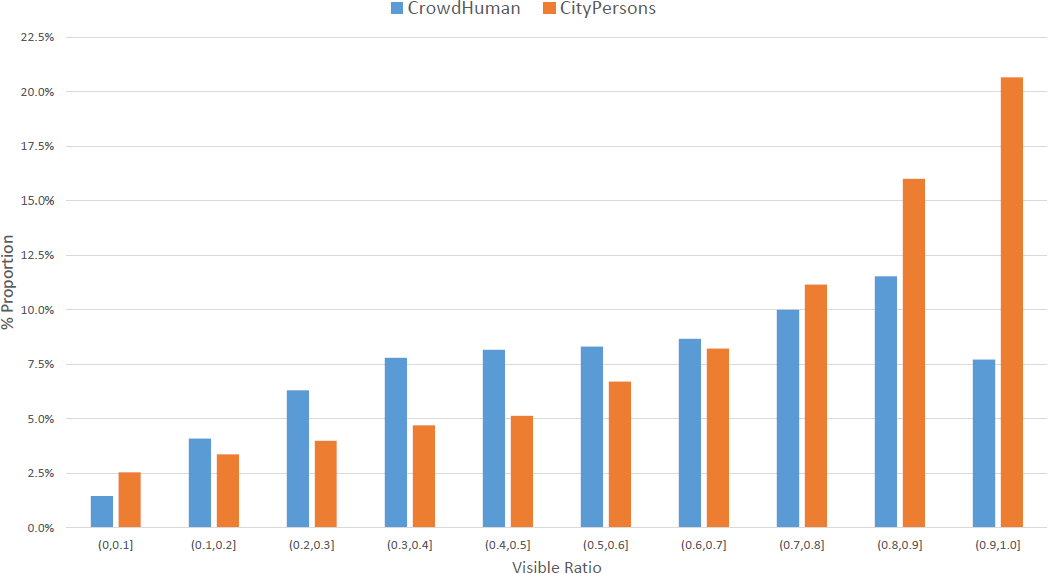
Comparison of the visible ratio between our CrowdHuman and CityPersons dataset.
Visible Ratio is defined as the ratio of visible bounding box to the full bounding box.















